Schedulers
CPU Time Sharing
When we discussed interrupts in Worksheet 3, we learned that they allow your computer to run multiple applications at the same time on a single CPU. When you have Excel, PowerPoint, and Chrome running at the same time on your laptop, the CPU is actually switching rapidly between these three programs.
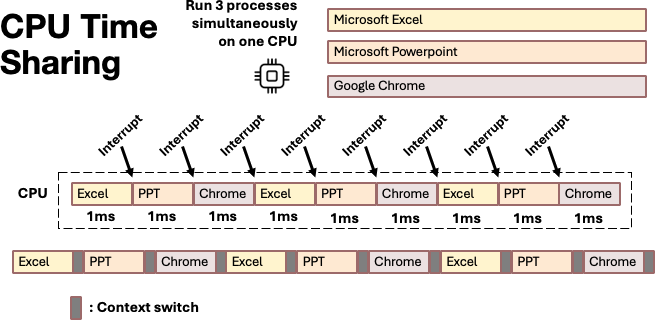
The question is: How long should each application be allowed to use the CPU before we interrupt it and switch to another? Each time an interrupt occurs to stop the currently running process, the kernel scheduler must make a decision about what to do next.
OS v.s Homework Scheduling
This analogy is adopted from Prof. Shiao‐Li Tsao’s Process Management lecture
Let’s use an analogy to understand CPU scheduling. How do you manage your own homework schedule. You have multiple assignments to complete, each with different deadlines and importance levels. Professors continue assigning new work while you’re still working on existing assignments. In this scenario, you face several scheduling decisions.
- What is the next homework assignment to work on? The scheduler also must decide which process should run next. Should you work on the assignment due tomorrow, or the more important project due next week? The scheduler must decide which process deserves CPU time based on various factors like priority, waiting time, and deadlines.
- When should you stop working on your current assignment? Perhaps you’ve been working on calculus for two hours and need a break, or maybe you realize you should switch to studying for tomorrow’s exam. The scheduler must decide when to preempt a running process (preempt means stop). This could be because the process has used up its time slice, a higher-priority process has become ready, or the current process is waiting for I/O.
- How long can you concentrate on one assignment before you fade out? This corresponds to the scheduling time quantum or time slice. Too short, and you spend more time switching between tasks than actually working. Too long, and other urgent tasks might be neglected.
- How much time do you spend deciding what to work on next? Every time you finish a task or decide to switch, you need a moment to make a choice. The scheduling algorithm also has an overhead: the time the CPU spends running the scheduler code itself to pick the next process to run.
- How much effort goes into switching from one assignment to another? You might need to close your calculus book, find your history notes, and mentally shift focus. This is similar to context switching overhead: the CPU must save the current process state and load the state of the next process.
- What decides the importance of each assignment? Some homework might be worth 30% of your grade, other homeworks just <1%. Processes have different priority levels. System processes might have higher priority than user applications.
Scheduler’s Goals
- Response Time is how quickly the system reacts to new event, like user’s keyboard input. When you edit in VS Code, you press
ton the keyboard and 2 seconds latertappears on the screen. This is laggy!! This means the system has a bad response time. - Throughput is the total amount of work the CPU completes over a period. You want to compile your code in three seconds, not in five seconds.
These two goals can conflict. To ensure a fast response time, the scheduler may need to interrupt a long-running task to quickly handle user input. This interruption improves the user’s perception of performance, but the context switch adds overhead and slows down the original task, which can decrease overall throughput.
There are other goals:
In real-time environments, such as embedded systems for automatic control in industry (for example robotics), the scheduler also must ensure that processes can meet deadlines; this is crucial for keeping the system stable. (Source: Wikipedia)
Preemptive vs. Non-Preemptive Scheduling
Modern operating systems use preemptive scheduling for time-sharing the CPU. In preemptive scheduling, the operating system can interrupt a running process and switch to another process, even if the current process hasn’t finished its work. This ensures that no single process can occupy the CPU all the time. When you’re typing in a word processor while a video is playing in the background and a file is downloading, preemptive scheduling ensures that each of these activities gets regular access to the CPU.
Non-preemptive (or cooperative) scheduling requires processes to voluntarily give up the CPU when they’re finished or when they need to wait for I/O. The process itself decides when to yield control back to the operating system. If the process 站著毛坑不拉屎, the whole system will hang there .
To understand why both preemptive and non-preemptive scheduling exist, we need to look at the historical context of computing and how different types of computer systems evolved to serve different needs. Early PC like the Apple Mac System 6/7 (1988-1991) and Microsoft’s DOS had very limited RAM (< 1MB) and slow processors like the Motorola 68000. At that time, users typically ran one main application at a time, like Microsoft Word or Photoshop. If Word is misbehaving, the whole system will enter blue screen, and only reboot can fix it. These systems used cooperative scheduling because cooperative scheduling avoided the overhead of frequent timer interrupts and context switches, which were more noticeable on slower hardware. The main application received all CPU time, while background applications made no progress until the active program voluntarily yielded control. If Photoshop was drawing a complex image, your email application wouldn’t fetch new messages until Photoshop finished and yielded the CPU. Here are some photos I took during a trip to a musuem in Netherland: applications are loaded from tape or cartridge like these and user just run this application the entire time without switching to others (there is no others). When you bought a Mac or PC, you were typically the only user, so if Word crashed, you simply rebooted. No big deal. But this is not ok if the computer must be shared with other people. In early Unix workstations, multiple users could log into the same machine. The kernel had no control over what kind of programs users might run, and it couldn’t trust all programs to be well-behaved and cooperatively yield the CPU. In this environment, one user’s infinite loop or poorly written program could completely lock out other users from the system. Unix systems must use preemptive scheduling to ensure users share CPU fairly. This continue to hold true until today. In data center server, there can be millions of processes running at the same time on one single machine that might have more than 100 CPU cores. If one user is doing crypto mining, he should not be able to bring down the entire machine.Cooperative scheduling in the early days



Preemptive scheduling prevents misbehaving processes
CPU v.s I/O Bursts
A scheduler cannot treat all processes equally because not all processes behave the same way. The execution of a typical process is a cycle of two phases: a CPU burst, where it performs computations, and an I/O burst, where it waits for an I/O operation to complete (e.g., reading from a disk, or waiting for a user to press a key). There are two types of programs
I/O-Bound Programs: have many short CPU bursts and long periods of waiting for I/O. A text editor like VS Code is a great example. It spends most of its time waiting for the user to type the next key. Most interactive, GUI applications fall into this category.
CPU-Bound Programs: have very long CPU bursts and are doing purely calculations. Examples include video rendering or compiling codes.
Do you have this experience? You play a shooting game (which is CPU-bound) and try to type a message, but the character you type take a long time to appear on screen? Each key you press generates an interrupt and creates a tiny, high-priority task: display this character. This task is extremely short and unlikely to use its entire time slice. If the scheduler doesn’t immediately pause the game to run this task, the keypress has to wait. And you will feel the lag.
To prevent this, scheduler increases the priority of interactive programs. When you press a key in VS Code, the OS wakes up the VS Code process, gives it a high priority, and the scheduler immediately preempts other lower-priority CPU-bound programs. The process runs its very short CPU burst to handle the input and then quickly goes back to waiting and release the CPU. Then, your computer feels responsive, even when a CPU-bound process is running in the background.
Priority Scheduling
The scheduler assigns a priority to each process. When it’s time to pick the next process to run, the scheduler chooses the one with the highest priority from the pool of ready processes. But a situation can happen: high-priority processes run all the time while low-priority processes might never get a chance to run. This is called starvation.
To prevent this, operating systems use dynamic priorities. Instead of a fixed priority, a process’s priority can change over its lifetime. For example, a process that has been waiting for a long time might have its priority gradually increased by the OS. This is called aging. This makes sure that eventually every process’s priority will become high enough to be scheduled. On the other hand, the priority of a process that has used all its time slice can be lowered to give other processes a chance.
Here are additional goals for priority scheduling:
- Fairness ensures every process gets proportional CPU time according to its priority
- Liveness ensures even the lowest-priority process gets a chance to run eventually gets a turn to run on the CPU within a finite amount of time. In other words, liveness means free from starvation
nice

In Linux, every process has a nice value that define its priority. It’s called “nice” because a process with a higher nice value is “nicer” to other processes on the system. It voluntarily runs at a lower priority.
The nice range is from -20 to +19:
- -20: The highest priority (least “nice”).
- +19: The lowest priority (most “nice”).
- 0: The default value inherited from the parent process.
If you want to compile a large software project or render a 4K video (both are very CPU-bound), you can start this process with a high nice value to ensure it doesn’t make your desktop laggy, like this:
$ nice -n 15 ./my-video-encoder
The Completely Fair Scheduler (CFS)
CFS has been the standard scheduler in the Linux kernel for a long time. Its goal is to achieve perfect fairness. If a single process is running, it would receive 100% of CPU time. If two processes are running, each would get 50% of CPU time. If 4 processes are running, each would get 25%, and so on.
CFS doesn’t use fixed time slices like Round-Robin Scheduling. CFS uses The A runqueue is the list of processes that are in the ready state. They are not waiting for I/O or sleeping. They are fully prepared to run and are just waiting for a CPU core to be released. CFS can pick the process with the lowest When timer interrupt occurs, CFS looks at the current process’s vruntime (virtual runtime) to track how long a process has been allowed to run on the CPU. CFS always picks the process with the lowest vruntime to run next.vruntime is weighted by nicenice value of a process decides how quickly that process’s vruntime increases. A high-priority process (with a low or negative nice value)’s vruntime increases more slowly than a normal process. Since its vruntime stays lower for longer, the scheduler will choose it more often. On the other hand, a low-priority process (with a high positive nice value)’s vruntime increases more quickly. Thus, it is scheduled less frequently. CFS’s mechanism gives more CPU time to more important tasks but still make sure low-priority task is not starved.How CFS make scheduling decision fast?
vruntime to run fast because it maintains its run queue with a red-black tree sorted by the vruntime. The process with the minimum vruntime is always the leftmost node.vruntime. If it exceeds a predefined budget, the process will be preempted if there are other runnable processes available. The process will also be preempted if the there is another process ready to run who has a smaller vruntime.
Multi-Core Scheduling
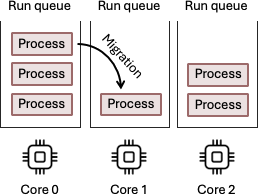
On a multi-core system, the scheduler doesn’t just pick the next task, it must also decide which CPU core to run it. Consider a 2-core system. Process A is running on Core 0 and has filled its super-fast L1 and L2 caches with its data and instructions. Suddenly, a timer interrupt preempts it. The CFS scheduler runs and finds process B now has the lowest The scheduler’s preference to keep a process on a core with a hot cache is known as soft affinity. It’s a “best effort” attempt, but the scheduler can override it if necessary to balance the system’s overall load. We can force the scheduler to always run a process in a specific CPU core. This is called process pinning. In Linux, you can use the This ensures that vruntime, so the kernel context switches to Process B to run on Core 0. Process A is now waiting in the runqueue, but no one is currently running on Core 1. Should the scheduler resume process A on CPU Core 1? This is known as task migration. Migrating to Core 1 would incur a significant performance penalty from cache misses, because all of process A’s data would need to be reloaded from slow main memory. Therefore, the scheduler will often prefer to let process A wait a little longer to resume on Core 0, where its data is still “hot” in the cache, because the performance benefit from more cache hits could be greater than the performance benefit of starting a few microseconds earlier on a different core.CPU Affinity
taskset command:$ taskset -c 0 ./my-processmy-process will always run on CPU core 0. This can improves that process’s performance because it might have better CPU cache hit rate, but there might be some CPU left idle.
Group Scheduling
Suppose you have 25 processes running, CFS will try to give each one an equal 4% share of the CPU. However, imagine that 20 of those processes belong to user A, 5 of them belong to user B. Then, it means that user A receives 80% of the total CPU power, but user B only gets 20%.
Group scheduling prevents this unfairness. It tries to be fair between groups: User A and User B’s process group each get 50% of CPU time. Then, group scheduling ensures fairness within each group. User A’s 50% share is divided equally among their 20 processes. User B’s 50% share is divided among the 5 processes.
Load Balancing
Suppose you have 4 CPU cores and 4 processes to run, you want each core to run one process so all of them can finish earlier. You don’t want one core to run 4 processes while the other three cores are idle. This is called Load Balancing.
This might sound simple. But running the load-balancing procedure can be very expensive. The scheduler might need to check multiple runqueues of many other cores and modify data that may be in another core’s cache.
The paper you are about to read explains that this difficulty. Try to understand Section 2.2 of the classic paper, “The Linux Scheduler: a Decade of Wasted Cores.” (Lozi et al. 2016) PDF of the paper Don’t worry if you don’t fully understand it. The motivation for per-core runqueues is that upon a context switch the core would access only its local runqueue, when it looks for a thread to run. Context switches are on a critical path, so they must be fast. Accessing only a core-local queue prevents the scheduler from making potentially expensive synchronized accesses, which would be required if it accessed a globally shared runqueue. Multiple kernel processes modifying the same run queue at the same time will cause problems. The kernel needs to maintain lock to prevent this, and this can reduce performance. That’s why Linux maintains a separate red-black tree run queue for each CPU core. But the problem is: some cores will become idle, some cores will be busy all the time. This is the load-balancing problem the paper is talking about. The scheduler is supposed to be work-conserving (meaning that the CPU is kept always busy, no idle time is wasted), but in practice CFS could not ensure this. The scheduler also doesn’t always steal ready process from other occupied core to run on a currently idle core. This is called work stealing. A strawman load-balancing algorithm would simply ensure that each runqueue has roughly the same number of threads. However, this is not necessarily what we want. Why? As we mention earlier, process migration might not be good because the performance benefit from more cache hits could be greater than the performance benefit of starting a few microseconds earlier on a different core. The paper also points out the Tickless Idle mechanism and why it might affect response time. In the old days, every CPU core got a regular “tick”. Timer interrupt arrives at a fixed frequency (say every millisecond). These ticks let the scheduler update time, decide if tasks should be switched, and check if load balancing is needed. But if a CPU core has no work, these ticks are wasteful. Waking up just to confirm “I’m still idle” costs energy. This is terrible for laptop and smartphone. So Linux introduced Tickless Idle. When a CPU core has nothing to do, the kernel can stop its periodic ticks and let it fall into a deep sleep state. This saves power. For example, if your phone is sitting in your pocket, you don’t want idle cores waking up a thousand times per second just to discover nothing has changed. But here’s the trade-off: a sleeping core does not check the system by itself anymore. If another core is overloaded, the idle core will not come to help unless it is explicitly woken up. That means another CPU has to send it a signal to say ’hey, wake up, I’ve got work for you.” This can create problems: one CPU might be busy drowning, while its neighbor stays 躺平 .The Linux Scheduler: a Decade of Wasted Cores
Power
Another goal of OS scheduler is to save power. This is very important for laptop and smartphone to have longer battery life.
CPUs from Intel, AMD, Apple, and ARM, all have different core types on a single CPU. They have high-performance cores, called “big” or P-cores, and power-efficient cores, known as “small” or E-cores.
- P-core is fast but power-hungry.
- E-cores is slower but energy-efficient.
補充資料: This article has a very interesting discussion on Apple Sillicon’s Scheduling
Now the decision the scheduler should make is even more complex. It should now decide where to put a process to save power but without sacrificing performance too much. Generally speaking, running a background process in E-core can save energy. It doesn’t matter whether it finishes in 2 or 10 seconds. But it is also possible that running it on P-core for 2 seconds consumes less total energy compared to taking 10 seconds on an E-core.

For example, your Anti-virus software scans files in background, running it on an E-core saves energy. Whether it finishes in 2 or 10 seconds doesn’t matter to the user. But sometimes, running the same task briefly on a P-core and letting it go back to sleep can actually use less total energy. A faster finish means the system can return to a deep idle state sooner.
“It is sometimes more efficient to get a job done quickly and go idle than it is to drag it out at a lower CPU frequency.” (LWN: Power-aware scheduling)
Energy efficiency is not always about stretching tasks out slowly at low power. Sometimes running fast is better.
“Schedulers must balance system throughput with energy efficiency; placing the right task on the right CPU is crucial for overall performance and power consumption.” (LWN: Energy-aware scheduling in Linux)
On systems with asymmetric cores, the scheduler has to know which tasks truly need a P-core’s performance, and which can live comfortably on an E-core. For example, a video encoding thread might demand high performance, while a background file sync can run on an E-core.
The key point is: power-aware scheduling is workload dependent. The “right” decision depends on how urgent the task is, how much energy each option consumes, and whether finishing sooner allows deeper idle states.